on
Post-Election Reflection
## Loading required package: ggplot2## Loading required package: lattice##
## Attaching package: 'caret'## The following objects are masked from 'package:Metrics':
##
## precision, recall1. A recap of model(s) and predictions
The specified prediction model in section (1) is a multivariate regression model that estimates the popular vote share of Democratic Party for House Representative elections using the past five House Representative election results from 2012 to 2020. The unit of observation is congressional districts in the U.S. Not all the variables are available for the 2012-2022 study period, so the total number of sample observations used to specify the multivariate regression model is 488. This is mainly due to the limited availability of raw data about expert ratings from “FiveThirtyEight.” The dependent variable is the Democratic Party vote share out of the total votes to two parties (Democratic and Republican). The proposed model has three groups of independent variables: (i) Political Environment captured by how competitive election is and who is in White House; (ii) Macroeconomic Performance in the U.S. represented by Consumer Price Level, and Labor Market situation (unemployment rate); (iii) Demographic Characteristics of Voting Age Population represented by shares of female, young voters in 20s, and white non-Hispanic voters. The coefficients for all variables except for the unemployment rate variable show the expected signs and are significant at the 5% level. (Details are explained in the following sections.) It is important to consider how close the election is when estimating the popular vote share since this can increase the voter turnout rate. Also, the President’s party historically tends to have disadvantages in House elections. National macroeconomic performance can serve as critical factors for voters as well. Demographic characteristics of voters are important to predict the election results, e.g., in an election where a majority of voters are more progressive such as younger voters, female, and minority in race, the Democratic party’s popular vote tends to increase.
According to the FiveThirtyEight prediction of the national popular vote for the 2022 House of Representatives election, the popular vote margin is in favor of the Republican party, ranging from 2.3% on Sep 23, 2022 to 6.6% on June 13. In other words, the margin has never been greater than 20%, indicating that the 2022 House Representative election is Toss-up election when measured by popular vote. That explains my choice for the value of the dummy variables of Close Election, Lean, Likely, or Solid for Democratic Candidate, and Democratic President (X1 is set to be one, while X2 is set to be zero).
To make a prediction of nationwide Democratic Party Vote Share of the two major party votes, the proposed multivariate regression model is used. For the 2022 House Representative Election, the most recent data available are used at national level from various data sources. Details are summarized in the table below.
US Popular Vote Prediction: The predicted nationwide Democratic Party vote share of 2022 House Representative Election is 50.56%, whereas the matching share for Republican Party is 49.44% (= 100% - 50.56%). Consequently, the margin between two major parties is expected to be 1.12%.
The proposed multivariate regression model predicted the national Democrat Vote Share in 2022 House Representative election, which is 50.56 Representative Election has its fit value of 50.55775% with the 95% of predictive interval ranging from 43.01576% (lower bound) to 58.09973% (upper bound). It means that the 2022 national Democratic vote share of the House election would fall in this predictive interval with 95% of probability.
## fit lwr upr
## 1 50.55775 43.01576 58.09973Nevada 3rd District Prediction: Additionally, the prediction for the most competitive district in Nevada (NV-3) was made using the proposed model. The demographic characteristics of the district (NV-3) and U.S. macroeconomic conditions with the expert rating for the election are used to estimate the popular vote share of the Democratic candidate. The predicted Democratic candidate (Susie Lee) vote share in NV-3 for the 2022 House Representative Election is 51.40%, whereas the matching share for the Republican candidate (April Becker) is 48.60% (= 100% - 51.40%). Consequently, the margin between two major parties is expected to be 2.8%.
pi_2022_NV3 = predict(lm_DVsh_US, newdata_2022_NV3, interval="predict", level =.95)
pi_2022_NV3## fit lwr upr
## 1 51.40132 43.77471 59.027922. A description of the accuracy of the model(s) – Graphs
The prediction model’s accuracy can be checked based on the gap between the prediction and the actual election results from the 2022 Midterm Election. The model works better with more accurate prediction for a specific congressional district (e.g., Nevada 3rd District) than the US popular vote.
US Popular Vote Prediction The predicted popular vote for Democratic Party = 50.56% The actual popular vote for Democratic Party = 48.42% When looking at the residual difference between the actual popular vote and my predicted vote, the prediction model overestimates the true Democratic popular vote share by 2.14%. But, the 95% prediction interval ranges from 43.02% to 58.10%, which includes the actual popular vote for Democratic Party.
Nevada 3rd District Prediction The predicted popular vote for Democratic Candidate = 51.40% The actual popular vote for Democratic Candidate = 51.98% The prediction model underestimates the popular vote share for Democratic candidate, Susie Lee, by 0.58%. But, the 95% prediction interval ranges from 43.77% to 59.03%, which includes the actual popular vote for Democratic Party.
## [1] 3.574183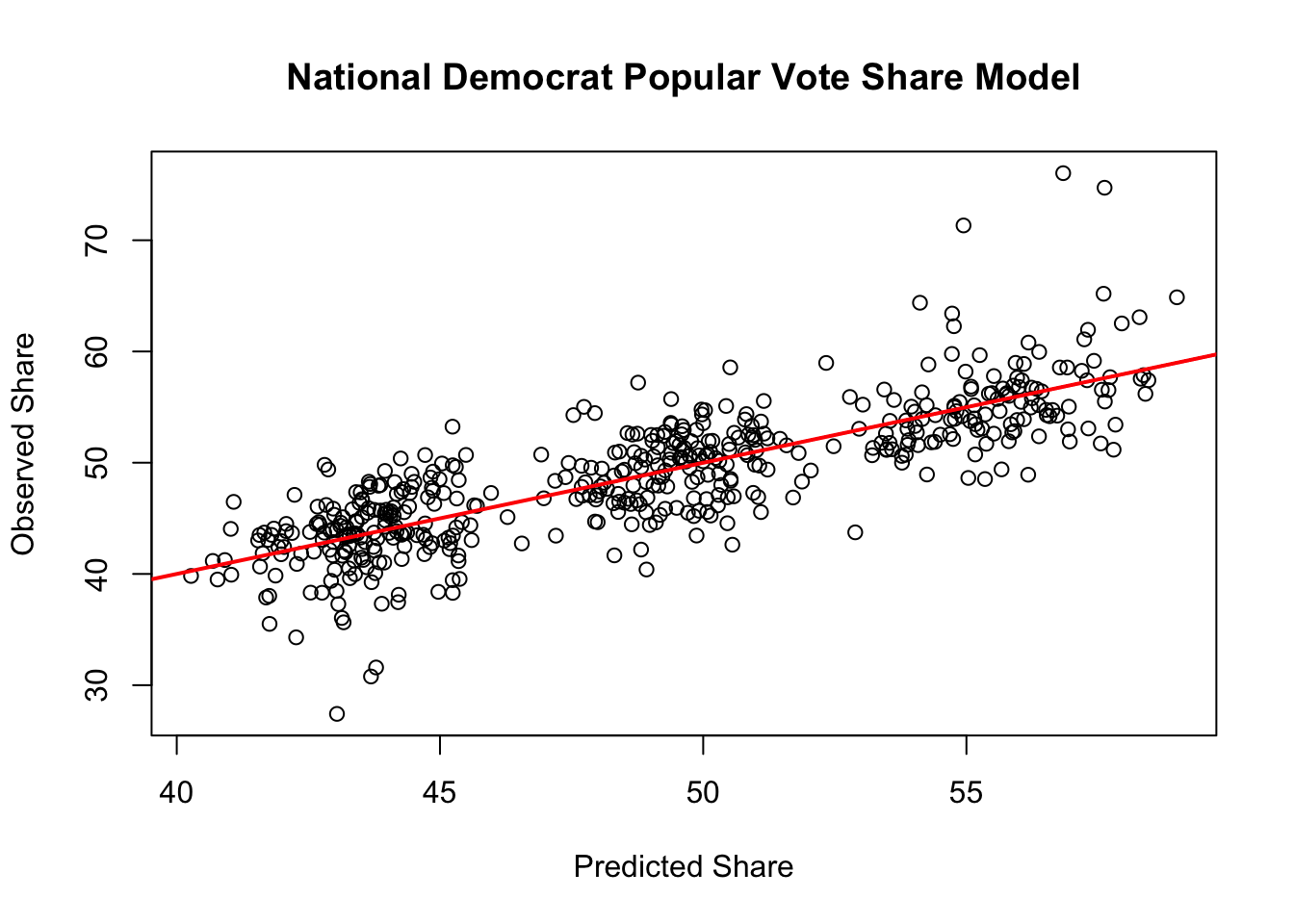
Overall, I am proud of the decently high levels of accuracy in my model. As one can see, the predicted values from my model fit well with previous elections’ actual results. In the graph shown above, I compared the predicted vote share for Democratic candidates of a congressional district at a given year to the actual vote share for the Democratic candidate from the congressional district in that year from the election results. In order to do that, I had to collect all the data (for each CD in a given year) that varies by CD and year, namely for the demographic variables. All other variables are national, meaning they varied only by year, since they are constant across all CDs in the U.S. Each point represents a single congressional district for different years with data from elections during 2012-2020. To note, some of the congressional districts changed depending on the available data. Still, each point denotes a different congressional district during a specific election and serves as one observation in our sample for the prediction model. The slope of the best fitted (red) line between ‘Predicted Values’ on the horizontal axis and ‘Observed Values’ on the vertical axis is less than 1. This indicates the prediction model’s general tendency for overestimation of Democratic popular vote share.
When validating the prediction model performance, the calculated RMSE of the model with all sample observations is 3.574183 (found above) that shows the average distance between the observed values and the predicted values of Democrat Vote Share (the dependent variable).
3. Proposed hypotheses for why the model(s) were inaccurate in the estimates or locations where it was inaccurate
Hypothesis 1: Null: Relative over-representativeness of specific demographic groups does not cause the overestimation of US popular vote share for Democratic Party. Alternative: Relative over-representativeness of specific demographic groups does cause the overestimation of US popular vote share for Democratic Party.
The second highest coefficient (positive and significant marginal effect) in the prediction model is from the “X20_29” variable (Share of Population (aged 20-29) among Total Voting Age Population). However, this variable does not consider the voting eligibility based on citizenship status, rather the variable includes all the population between 20 years old and 29 years old. The Hispanic population is much younger with the median age of 29.8 compared to 38.5 for all Americans (source: https://usafacts.org/articles/demographics-hispanic-americans/). Additionally, 22% of Hispanics are not U.S. citizens (source: https://usafacts.org/articles/demographics-hispanic-americans/). Consequently, the variable might have over-represented the young voters in their 20s that contributed to the overestimation of Democratic popular vote share.
The Voting Eligible Population variable would likely be a better predictor in capturing the relationship between the Share of the Population aged 20-29 and its effect on the overall Democrat Majority Vote Share. The Pew Research Center found that scholars and political scientists have preferred using the VEP measure as it more accurately predicts voter turnout. Additionally, the U.S. Elections Project, a project collecting data to help predict voter turnout headed by Michael McDonald, a political scientist at the University of Florida, claims there are four primary reasons why the VEP is a better turnout rate denominator than the VAP. “First, the most valid turnout rates over time and across states are calculated using the voting-eligible population. Secondly, declining turnout rates, post-1971, are entirely explained by the increase in the ineligible population. In 1972, the non-citizen population of the United States was less than 2 percent of VAP and in 2004 it was nearly 8.5 percent of VAP. The percent of non-felons among the VAP have increased from .5 to about 1 percent of the VAP since the mid-1980s. Thirdly, using VEP turnout rates, recent presidential elections have returned to their levels during the high participation period in the 1950s and 1960s. And lastly state turnout rates are not comparable using VAP since the ineligible population is not uniformly distributed across the United States. For example, nearly 20 percent of California’s voting-age population is ineligible to vote because they are felons or are not citizens.”
Also, popular national models such as 538 and The Economistpredict voter turnout and predictions with demographics based on the VEP instead of the VAP. Nate Silver claims that “Competitive races tend to produce higher turnout than noncompetitive ones. Projecting turnout is important in understanding the relationship between the national popular vote and the number of seats that each party might gain or lose.” To preserve the accuracy in predicting turnout, the 538 models base their projections in each race on factors such as the VEP and turnout in past midterms and presidential races. And considering how well these forecasts have done and their credibility in election forecasting, I have reason to believe that my model, based on VEP, will also do well (at least better than with VAP in predicting the election outcome). As long as I have the data available, I would use VEP as a more reliable predictor of both turnout and party vote share.
The other demographic I would look into is the cohort of female voters, specifically those that are able to cast their votes. largest positive and significant marginal effect among the independent variables is from the “female” variable (Share of Female Population among Total Voting Age Population). Again, not all female population over 18 years old are U.S. citizens and eligible to vote. According to the 2021 ACS (American Community Survey) 1-year Estimates Data, approximately 7.2% of females over 18 years old in the U.S. are not U.S. citizens.
Hypothesis 2: Null: Use of scale (continuous), not dummy, variable for expert rating from “FiveThirtyEight” does not enhance the model predictability for US popular vote share for Democratic Party. Alternative: Use of scale (continuous), not dummy, variable for expert rating from “FiveThirtyEight” does enhance the model predictability for US popular vote share for Democratic Party.
The two political environment variables are created as dummy variables and both have positive and significant marginal effects in the prediction model. The “Close_E_D” variable is for close (toss-up) election dummy, while “LLS_D” variable is for lean, likely, or solid for Democrat dummy. At the national level, the popular vote margin between Democrat and Republican rarely exceeds 20%. Therefore, the prediction model always takes the value of 1 for these two dummy variables at national level popular vote share prediction. If scale (continuous), not dummy, variables can be used, the model predictability may improve.
4. Proposed quantitative tests that could test these hypotheses
Quantitative Test for Hypothesis 1: - A new multivariate regression model can be specified using a set of new demographic variables considering voter eligibility. - Compare RMSE of the original model to that of the new model to determine the better performing model. A model with a lower RMSE predicts better. Other measures such as R-square for the overall model performance can be used to test if a model has lower error (or less likely to overestimate). - The Diebold-Mariano (DM) test can be used to compare predictive accuracy of the original and the new models. Quantitative Test for Hypothesis 2: - A new multivariate regression model can be specified using a set of the new and refined scale (not dummy) variables of expert rating data. - Compare RMSE of the original model to that of the new model to determine the better performing model. A model with a lower RMSE predicts better. Other measures such as R-square for the overall model performance can be used to test if a model has lower error (or less likely to overestimate). - The Diebold-Mariano (DM) test can be used to compare predictive accuracy of the original and the new models.
5. A description of how I might change the model if I were to do it again
I may improve the predictive power of the proposed model by employing a new set of data for model specification. The newly specified model will yield a new set of coefficients (marginal effects) for estimating the Democrat popular vote share.
For demographic variables, I would use the ACS 1-year estimate dataset that enables the crosstabulation of race and gender with citizenship status. This is available at Congressional District Level. The denominator for calculating the share of a specific demographic group is no longer the voting-age population; rather it will be eligible voters with citizenship. By doing this, over-representation of specific demographic groups such as voters in their 20s can be controlled. Accordingly, the related overestimation problems of US popular vote share for Democratic party can be corrected. This will contribute to the enhanced model predictability.
For expert rating variables, average rating that ranges from 1 (solid Democrat) to 7 (solid Republican) can be rescaled using an average percentage of poll data. In the current prediction model, I developed 2 dummy variables (Close_E_D and LLS_D). Each does not directly use the average approval percentage from the poll survey. In other words, it simplifies the 1 to 7 scale into the dummy variables. However, with access to the actual percentage of approval for each CD in each election, I could have used the average percentage approval rate for a Democratic candidate in each CD for a given election year. This will be a better use of popular polling data at congressional district level. The newly revised model with this average percentage of poll data will produce higher accuracy, indicating the enhanced predictability of my model.